2.1. Events and Simulator¶
ns-3 is a discrete-event network simulator. Conceptually, the simulator keeps track of a number of events that are scheduled to execute at a specified simulation time. The job of the simulator is to execute the events in sequential time order. Once the completion of an event occurs, the simulator will move to the next event (or will exit if there are no more events in the event queue). If, for example, an event scheduled for simulation time “100 seconds” is executed, and the next event is not scheduled until “200 seconds”, the simulator will immediately jump from 100 seconds to 200 seconds (of simulation time) to execute the next event. This is what is meant by “discrete-event” simulator.
To make this all happen, the simulator needs a few things:
a simulator object that can access an event queue where events are stored and that can manage the execution of events
a scheduler responsible for inserting and removing events from the queue
a way to represent simulation time
the events themselves
This chapter of the manual describes these fundamental objects (simulator, scheduler, time, event) and how they are used.
2.1.1. Event¶
An event represents something that changes the simulation status, i.e., between two events the simulation status does not change, and the event will likely change it (it could also not change anything).
Note that another way to understand an event is to consider it as a delayed function call. With the due differences, a discrete event simulation is not much different from a “normal” program where the functions are not called immediately, but are marked with a “time”, and the time is used to decide the order of the functions execution.
The time, of course, is a simulated time, and is quite different from the “real” time. Depending on the simulation complexity the simulated time can advance faster or slower then the “real” time, but like a “real” time can only go forward.
An example of an event is the reception of a packet, or the expiration of a timer.
An event is represented by:
The time at which the event will happen
A pointer to the function that will “handle” the event,
The parameters of the function that will handle the event (if any),
Other internal structures.
An event is scheduled through a call to Simulator::Schedule, and once
scheduled, it can be canceled or removed.
Removal implies removal from the scheduler data structure, while cancel
keeps them in the data structure but sets a boolean flag that suppresses
calling the bound event function at the scheduled time. When an event is
scheduled by the Simulator, an EventId is returned. The client may use
this event ID to later cancel or remove the event; see the example program
src/core/examples/sample-simulator.{cc,py} for example usage.
Cancelling an event is typically less computationally expensive than
removing it, but cancelled events consumes more memory in the scheduler
data structure, which might impact its performances.
Events are stored by the simulator in a scheduler data structure. Events are handled in increasing order of simulator time, and in the case of two events with the same scheduled time, the event with the lowest unique ID (a monotonically increasing counter) will be handled first. In other words tied events are handled in FIFO order.
Note that concurrent events (events that happen at the very same time) are unlikely in a real system - not to say impossible. In ns-3 concurrent events are common for a number of reasons, one of them being the time representation. While developing a model this must be carefully taken into account.
During the event execution, the simulation time will not advance, i.e., each event is executed in zero time. This is a common assumption in discrete event simulations, and holds when the computational complexity of the operations executed in the event is negligible. When this assumption does not hold, it is necessary to schedule a second event to mimic the end of the computationally intensive task.
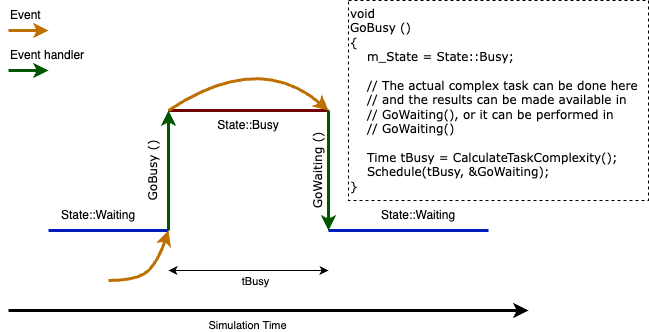
As an example, suppose to have a device that receives a packet and has to perform a complex analysis on it (e.g., an image processing task). The sequence of events will be:
T(t) - Packet reception and processing, save the result somewhere, and schedule an event in (t+d) marking the end of the data processing.
T(t+d) - Retrieve the data, and do other stuff based them.
So, even if the data processing actually did return a result in the execution of the first event, the data is considered valid only after the second event.
The image below can be useful to clarify the idea.
2.1.2. Simulator¶
The Simulator class is the public entry point to access event scheduling
facilities. Once a couple of events have been scheduled to start the
simulation, the user can start to execute them by entering the simulator
main loop (call Simulator::Run). Once the main loop starts running, it
will sequentially execute all scheduled events in order from oldest to
most recent until there are either no more events left in the event
queue or Simulator::Stop has been called.
To schedule events for execution by the simulator main loop, the Simulator class provides the Simulator::Schedule* family of functions.
Handling event handlers with different signatures
These functions are declared and implemented as C++ templates to handle automatically the wide variety of C++ event handler signatures used in the wild. For example, to schedule an event to execute 10 seconds in the future, and invoke a C++ method or function with specific arguments, you might write this:
void handler(int arg0, int arg1)
{
std::cout << "handler called with argument arg0=" << arg0 << " and
arg1=" << arg1 << std::endl;
}
Simulator::Schedule(Seconds(10), &handler, 10, 5);
Which will output:
handler called with argument arg0=10 and arg1=5
Of course, these C++ templates can also handle transparently member methods on C++ objects:
To be completed: member method example
Notes:
the ns-3 Schedule methods recognize automatically functions and methods only if they take less than 5 arguments. If you need them to support more arguments, please, file a bug report.
Readers familiar with the term ‘fully-bound functors’ will recognize the Simulator::Schedule methods as a way to automatically construct such objects.
Common scheduling operations
The Simulator API was designed to make it really simple to schedule most events. It provides three variants to do so (ordered from most commonly used to least commonly used):
Schedulemethods which allow you to schedule an event in the future by providing the delay between the current simulation time and the expiration date of the target event.ScheduleNowmethods which allow you to schedule an event for the current simulation time: they will execute _after_ the current event is finished executing but _before_ the simulation time is changed for the next event.ScheduleDestroymethods which allow you to hook in the shutdown process of the Simulator to cleanup simulation resources: every ‘destroy’ event is executed when the user calls the Simulator::Destroy method.
Maintaining the simulation context
There are two basic ways to schedule events, with and without context. What does this mean?
Simulator::Schedule(Time const &time, MEM mem_ptr, OBJ obj);
vs.
Simulator::ScheduleWithContext(uint32_t context, Time const &time, MEM mem_ptr, OBJ obj);
Readers who invest time and effort in developing or using a non-trivial simulation model will know the value of the ns-3 logging framework to debug simple and complex simulations alike. One of the important features that is provided by this logging framework is the automatic display of the network node id associated with the ‘currently’ running event.
The node id of the currently executing network node is in fact tracked by the Simulator class. It can be accessed with the Simulator::GetContext method which returns the ‘context’ (a 32-bit integer) associated and stored in the currently-executing event. In some rare cases, when an event is not associated with a specific network node, its ‘context’ is set to 0xffffffff.
To associate a context to each event, the Schedule, and ScheduleNow methods automatically reuse the context of the currently-executing event as the context of the event scheduled for execution later.
In some cases, most notably when simulating the transmission of a packet from a node to another, this behavior is undesirable since the expected context of the reception event is that of the receiving node, not the sending node. To avoid this problem, the Simulator class provides a specific schedule method: ScheduleWithContext which allows one to provide explicitly the node id of the receiving node associated with the receive event.
XXX: code example
In some very rare cases, developers might need to modify or understand how the context (node id) of the first event is set to that of its associated node. This is accomplished by the NodeList class: whenever a new node is created, the NodeList class uses ScheduleWithContext to schedule a ‘initialize’ event for this node. The ‘initialize’ event thus executes with a context set to that of the node id and can use the normal variety of Schedule methods. It invokes the Node::Initialize method which propagates the ‘initialize’ event by calling the DoInitialize method for each object associated with the node. The DoInitialize method overridden in some of these objects (most notably in the Application base class) will schedule some events (most notably Application::StartApplication) which will in turn scheduling traffic generation events which will in turn schedule network-level events.
Notes:
Users need to be careful to propagate DoInitialize methods across objects by calling Initialize explicitly on their member objects
The context id associated with each ScheduleWithContext method has other uses beyond logging: it is used by an experimental branch of ns-3 to perform parallel simulation on multicore systems using multithreading.
The Simulator::* functions do not know what the context is: they merely make sure that whatever context you specify with ScheduleWithContext is available when the corresponding event executes with ::GetContext.
It is up to the models implemented on top of Simulator::* to interpret the context value. In ns-3, the network models interpret the context as the node id of the node which generated an event. This is why it is important to call ScheduleWithContext in ns3::Channel subclasses because we are generating an event from node i to node j and we want to make sure that the event which will run on node j has the right context.
2.1.2.1. Available Simulator Engines¶
ns-3 supplies two different types of basic simulator engine to manage event execution. These are derived from the abstract base class SimulatorImpl:
DefaultSimulatorImpl This is a classic sequential discrete event simulator engine which uses a single thread of execution. This engine executes events as fast as possible.
DistributedSimulatorImpl This is a classic YAWNS distributed (“parallel”) simulator engine. By labeling and instantiating your model components appropriately this engine will execute the model in parallel across many compute processes, yet in a time-synchronized way, as if the model had executed sequentially. The two advantages are to execute models faster and to execute models too large to fit in one compute node. This engine also attempts to execute as fast as possible.
NullMessageSimulatorImpl This implements a variant of the Chandy- Misra-Bryant (CMB) null message algorithm for parallel simulation. Like DistributedSimulatorImpl this requires appropriate labeling and instantiation of model components. This engine attempts to execute events as fast as possible.
You can choose which simulator engine to use by setting a global variable, for example:
GlobalValue::Bind("SimulatorImplementationType",
StringValue("ns3::DistributedSimulatorImpl"));
or by using a command line argument
$ ./ns3 run "... --SimulatorImplementationType=ns3::DistributedSimulatorImpl"
In addition to the basic simulator engines there is a general facility used to build “adapters” which provide small behavior modifications to one of the core SimulatorImpl engines. The adapter base class is SimulatorAdapter, itself derived from SimulatorImpl. SimulatorAdapter uses the PIMPL (pointer to implementation) idiom to forward all calls to the configured base simulator engine. This makes it easy to provide small customizations just by overriding the specific Simulator calls needed, and allowing SimulatorAdapter to handle the rest.
There are few places where adapters are used currently:
RealtimeSimulatorImpl This adapter attempts to execute in real time by pacing the wall clock evolution. This pacing is “best effort”, meaning actual event execution may not occur exactly in sync, but close to it. This engine is normally only used with the DefaultSimulatorImpl, but it can be used to keep a distributed simulation synchronized with real time. See the RealTime chapter.
VisualSimulatorImpl This adapter starts a live visualization of the running simulation, showing the network graph and each packet traversing the links.
LocalTimeSimulatorImpl This adapter enables attaching noisy local clocks to Nodes, then scheduling events with respect to the local noisy clock, instead of relative to the true simulator time.
In addition to the PIMPL idiom of SimulatorAdapter there is a special per-event customization hook:
SimulatorImpl::PreEventHook( const EventId & id)
One can use this to perform any housekeeping actions before the next event actually executes.
The distinction between a core engine and an adapter is the following: there can only ever be one core engine running, while there can be several adapters chained up each providing a variation on the base engine execution. For example one can use noisy local clocks with the real time adapter.
A single adapter can be added on top of the DefaultSimulatorImpl by the same two methods above: binding the “SimulatorImplementationType” global value or using the command line argument. To chain multiple adapters a different approach must be used; see the SimulatorAdapter::AddAdapter() API documentation.
The simulator engine type can be set once, but must be set before the first call to the Simulator() API. In practice, since some models have to schedule their start up events when they are constructed, this means generally you should set the engine type before instantiating any other model components.
The engine type can be changed after Simulator::Destroy() but before any additional calls to the Simulator API, for instance when executing multiple runs in a single ns-3 invocation.
2.1.3. Time¶
ns-3 internally represents simulation times and durations as 64-bit signed integers (with the sign bit used for negative durations). The time values are interpreted with respect to a “resolution” unit in the customary SI units: fs, ps, ns, us, ms, s, min, h, d, y. The unit defines the minimum Time value. It can be changed once before any calls to Simulator::Run(). It is not stored with the 64-bit time value itself.
Times can be constructed from all standard numeric types (using the configured default unit) or with explicit units (as in Time MicroSeconds (uint64_t value)). Times can be compared, tested for sign or equality to zero, rounded to a given unit, converted to standard numeric types in specific units. All basic arithmetic operations are supported (addition, subtraction, multiplication or division by a scalar (numeric value)). Times can be written to/read from IO streams. In the case of writing it is easy to choose the output unit, different from the resolution unit.
Here are examples of common usage:
Time t1 = MilliSeconds(1500); // 1.5 s = 1500 ms
Time t2 = MicroSeconds(500); // 500 microseconds
Time t3 = t1 + t2; // arithmetic
Time t4 = t3 * 2; // multiplication
if (t4 > Seconds(3))
{
std::cout << "t4 is greater than 3 seconds\n";
}
double ms = t4.GetMilliSeconds(); // convert to double in ms
std::cout << t4.As(Time::MS) << "\n"; // stream with specific unit
Note
When using floating-point values with constructors like Seconds(1.5),
users should be aware that values smaller than the current resolution
will be rounded. For example, if the resolution is set to nanoseconds,
values like Seconds(1e-10) will be rounded to zero.
Consider inspecting Time::SetResolution() and using methods like
GetNanoSeconds() to understand how sub-resolution values behave in practice.
When calling Time::SetResolution(), there is a trade-off between
the precision of time measurements and the maximum simulation time
span that can be represented. Finer resolutions (like femtoseconds)
allow for more precise timing but reduce the maximum representable
duration.
Resolution Unit |
Smallest Step |
Approximate Max Time Span |
|---|---|---|
Seconds |
1 s |
~2.9 × 10¹¹ years |
Milliseconds |
1 ms |
~2.9 × 10⁸ years |
Microseconds |
1 µs |
~2.9 × 10⁵ years |
Nanoseconds |
1 ns |
~292 years |
Picoseconds |
1 ps |
~107 days |
Femtoseconds |
1 fs |
~2.6 hours |
2.1.4. Scheduler¶
The main job of the Scheduler classes is to maintain the priority queue of future events. The scheduler can be set with a global variable, similar to choosing the SimulatorImpl:
GlobalValue::Bind("SchedulerType",
StringValue("ns3::DistributedSimulatorImpl"));
The scheduler can be changed at any time via Simulator::SetScheduler(). The default scheduler is MapScheduler which uses a std::map<> to store events in time order.
Because event distributions vary by model there is no one best strategy for the priority queue, so ns-3 has several options with differing tradeoffs. The example utils/bench-scheduler.c can be used to test the performance for a user-supplied event distribution. For modest execution times (less than an hour, say) the choice of priority queue is usually not significant; configuring the build type to optimized is much more important in reducing execution times.
The available scheduler types, and a summary of their time and space complexity on Insert() and RemoveNext(), are listed in the following table. See the individual Scheduler API pages for details on the complexity of the other API calls.
Scheduler Type |
Complexity |
||||
|---|---|---|---|---|---|
SchedulerImpl Type |
Method |
Time |
Space |
||
Insert() |
RemoveNext() |
Overhead |
Per Event |
||
CalendarScheduler |
<std::list> [] |
Constant |
Constant |
24 bytes |
16 bytes |
HeapScheduler |
Heap on std::vector |
Logarithmic |
Logarithmic |
24 bytes |
0 |
ListScheduler |
std::list |
Linear |
Constant |
24 bytes |
16 bytes |
MapScheduler |
st::map |
Logarithmic |
Constant |
40 bytes |
32 bytes |
PriorityQueueScheduler |
std::priority_queue<,std::vector> |
Logarithmic |
Logarithms |
24 bytes |
0 |