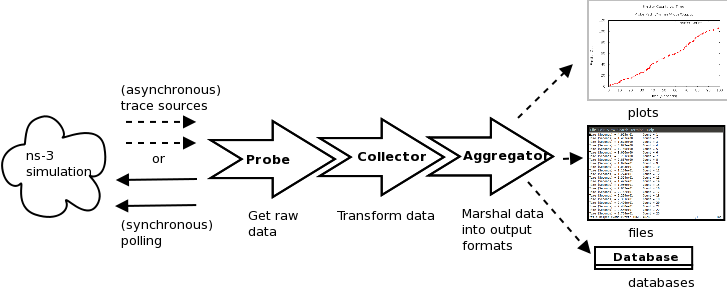
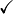Background
This chapter may be skipped by readers familiar with the basics of
software testing.
Writing defect-free software is a difficult proposition. There are many
dimensions to the problem and there is much confusion regarding what is
meant by different terms in different contexts. We have found it worthwhile
to spend a little time reviewing the subject and defining some terms.
Software testing may be loosely defined as the process of executing a program
with the intent of finding errors. When one enters a discussion regarding
software testing, it quickly becomes apparent that there are many distinct
mind-sets with which one can approach the subject.
For example, one could break the process into broad functional categories
like ‘’correctness testing,’’ ‘’performance testing,’’ ‘’robustness testing’’
and ‘’security testing.’’ Another way to look at the problem is by life-cycle:
‘’requirements testing,’’ ‘’design testing,’’ ‘’acceptance testing,’’ and
‘’maintenance testing.’’ Yet another view is by the scope of the tested system.
In this case one may speak of ‘’unit testing,’’ ‘’component testing,’’
‘’integration testing,’’ and ‘’system testing.’’ These terms are also not
standardized in any way, and so ‘’maintenance testing’’ and ‘’regression
testing’’ may be heard interchangeably. Additionally, these terms are often
misused.
There are also a number of different philosophical approaches to software
testing. For example, some organizations advocate writing test programs
before actually implementing the desired software, yielding ‘’test-driven
development.’’ Some organizations advocate testing from a customer perspective
as soon as possible, following a parallel with the agile development process:
‘’test early and test often.’’ This is sometimes called ‘’agile testing.’’ It
seems that there is at least one approach to testing for every development
methodology.
The ns-3 project is not in the business of advocating for any one of
these processes, but the project as a whole has requirements that help inform
the test process.
Like all major software products, ns-3 has a number of qualities that
must be present for the product to succeed. From a testing perspective, some
of these qualities that must be addressed are that ns-3 must be
‘’correct,’’ ‘’robust,’’ ‘’performant’’ and ‘’maintainable.’’ Ideally there
should be metrics for each of these dimensions that are checked by the tests
to identify when the product fails to meet its expectations / requirements.
Correctness
The essential purpose of testing is to determine that a piece of software
behaves ‘’correctly.’’ For ns-3 this means that if we simulate
something, the simulation should faithfully represent some physical entity or
process to a specified accuracy and precision.
It turns out that there are two perspectives from which one can view
correctness. Verifying that a particular model is implemented according
to its specification is generically called verification. The process of
deciding that the model is correct for its intended use is generically called
validation.
Validation and Verification
A computer model is a mathematical or logical representation of something. It
can represent a vehicle, an elephant (see
David Harel’s talk about modeling an elephant at SIMUTools 2009, or a networking card. Models can also represent
processes such as global warming, freeway traffic flow or a specification of a
networking protocol. Models can be completely faithful representations of a
logical process specification, but they necessarily can never completely
simulate a physical object or process. In most cases, a number of
simplifications are made to the model to make simulation computationally
tractable.
Every model has a target system that it is attempting to simulate. The
first step in creating a simulation model is to identify this target system and
the level of detail and accuracy that the simulation is desired to reproduce.
In the case of a logical process, the target system may be identified as ‘’TCP
as defined by RFC 793.’’ In this case, it will probably be desirable to create
a model that completely and faithfully reproduces RFC 793. In the case of a
physical process this will not be possible. If, for example, you would like to
simulate a wireless networking card, you may determine that you need, ‘’an
accurate MAC-level implementation of the 802.11 specification and [...] a
not-so-slow PHY-level model of the 802.11a specification.’‘
Once this is done, one can develop an abstract model of the target system. This
is typically an exercise in managing the tradeoffs between complexity, resource
requirements and accuracy. The process of developing an abstract model has been
called model qualification in the literature. In the case of a TCP
protocol, this process results in a design for a collection of objects,
interactions and behaviors that will fully implement RFC 793 in ns-3.
In the case of the wireless card, this process results in a number of tradeoffs
to allow the physical layer to be simulated and the design of a network device
and channel for ns-3, along with the desired objects, interactions and behaviors.
This abstract model is then developed into an ns-3 model that
implements the abstract model as a computer program. The process of getting the
implementation to agree with the abstract model is called model
verification in the literature.
The process so far is open loop. What remains is to make a determination that a
given ns-3 model has some connection to some reality – that a model is an
accurate representation of a real system, whether a logical process or a physical
entity.
If one is going to use a simulation model to try and predict how some real
system is going to behave, there must be some reason to believe your results –
i.e., can one trust that an inference made from the model translates into a
correct prediction for the real system. The process of getting the ns-3 model
behavior to agree with the desired target system behavior as defined by the model
qualification process is called model validation in the literature. In the
case of a TCP implementation, you may want to compare the behavior of your ns-3
TCP model to some reference implementation in order to validate your model. In
the case of a wireless physical layer simulation, you may want to compare the
behavior of your model to that of real hardware in a controlled setting,
The ns-3 testing environment provides tools to allow for both model
validation and testing, and encourages the publication of validation results.
Robustness
Robustness is the quality of being able to withstand stresses, or changes in
environments, inputs or calculations, etc. A system or design is ‘’robust’’
if it can deal with such changes with minimal loss of functionality.
This kind of testing is usually done with a particular focus. For example, the
system as a whole can be run on many different system configurations to
demonstrate that it can perform correctly in a large number of environments.
The system can be also be stressed by operating close to or beyond capacity by
generating or simulating resource exhaustion of various kinds. This genre of
testing is called ‘’stress testing.’‘
The system and its components may be exposed to so-called ‘’clean tests’’ that
demonstrate a positive result – that is that the system operates correctly in
response to a large variation of expected configurations.
The system and its components may also be exposed to ‘’dirty tests’’ which
provide inputs outside the expected range. For example, if a module expects a
zero-terminated string representation of an integer, a dirty test might provide
an unterminated string of random characters to verify that the system does not
crash as a result of this unexpected input. Unfortunately, detecting such
‘’dirty’’ input and taking preventive measures to ensure the system does not
fail catastrophically can require a huge amount of development overhead. In
order to reduce development time, a decision was taken early on in the project
to minimize the amount of parameter validation and error handling in the
ns-3 codebase. For this reason, we do not spend much time on dirty
testing – it would just uncover the results of the design decision we know
we took.
We do want to demonstrate that ns-3 software does work across some set
of conditions. We borrow a couple of definitions to narrow this down a bit.
The domain of applicability is a set of prescribed conditions for which
the model has been tested, compared against reality to the extent possible, and
judged suitable for use. The range of accuracy is an agreement between
the computerized model and reality within a domain of applicability.
The ns-3 testing environment provides tools to allow for setting up
and running test environments over multiple systems (buildbot) and provides
classes to encourage clean tests to verify the operation of the system over the
expected ‘’domain of applicability’’ and ‘’range of accuracy.’‘
Maintainability
A software product must be maintainable. This is, again, a very broad
statement, but a testing framework can help with the task. Once a model has
been developed, validated and verified, we can repeatedly execute the suite
of tests for the entire system to ensure that it remains valid and verified
over its lifetime.
When a feature stops functioning as intended after some kind of change to the
system is integrated, it is called generically a regression.
Originally the
term regression referred to a change that caused a previously fixed bug to
reappear, but the term has evolved to describe any kind of change that breaks
existing functionality. There are many kinds of regressions that may occur
in practice.
A local regression is one in which a change affects the changed component
directly. For example, if a component is modified to allocate and free memory
but stale pointers are used, the component itself fails.
A remote regression is one in which a change to one component breaks
functionality in another component. This reflects violation of an implied but
possibly unrecognized contract between components.
An unmasked regression is one that creates a situation where a previously
existing bug that had no affect is suddenly exposed in the system. This may
be as simple as exercising a code path for the first time.
A performance regression is one that causes the performance requirements
of the system to be violated. For example, doing some work in a low level
function that may be repeated large numbers of times may suddenly render the
system unusable from certain perspectives.
The ns-3 testing framework provides tools for automating the process
used to validate and verify the code in nightly test suites to help quickly
identify possible regressions.
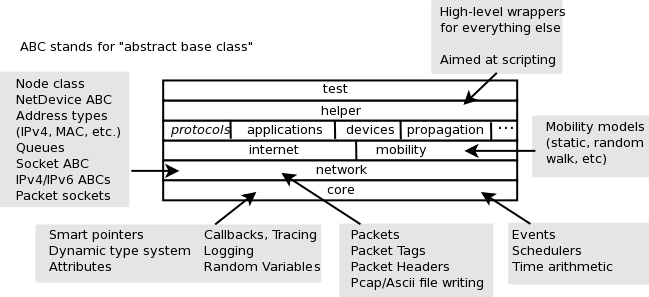
Testing framework
ns-3 consists of a simulation core engine, a set of models, example programs,
and tests. Over time, new contributors contribute models, tests, and
examples. A Python test program test.py serves as the test
execution manager; test.py can run test code and examples to
look for regressions, can output the results into a number of forms, and
can manage code coverage analysis tools. On top of this, we layer
buildslaves that are automated build robots that perform
robustness testing by running the test framework on different systems
and with different configuration options.
Buildslaves
At the highest level of ns-3 testing are the buildslaves (build robots).
If you are unfamiliar with
this system look at https://ns-buildmaster.ee.washington.edu:8010/.
This is an open-source automated system that allows ns-3 to be rebuilt
and tested daily. By running the buildbots on a number
of different systems we can ensure that ns-3 builds and executes
properly on all of its supported systems.
Users (and developers) typically will not interact with the buildslave system other
than to read its messages regarding test results. If a failure is detected in
one of the automated build and test jobs, the buildbot will send an email to the
ns-commits mailing list. This email will look something like
In the full details URL shown in the email, one can find links to the detailed test output.
The buildslave system will do its job quietly if there are no errors, and the
system will undergo build and test cycles every day to verify that all is well.
Test.py
The buildbots use a Python program, test.py, that is responsible for
running all of the tests and collecting the resulting reports into a human-
readable form. This program is also available for use by users and developers
as well.
test.py is very flexible in allowing the user to specify the number
and kind of tests to run; and also the amount and kind of output to generate.
Before running test.py, make sure that ns3’s examples and tests
have been built by doing the following
$ ./waf configure --enable-examples --enable-tests
$ ./waf build
By default, test.py will run all available tests and report status
back in a very concise form. Running the command
will result in a number of PASS, FAIL, CRASH or SKIP
indications followed by the kind of test that was run and its display name.
Waf: Entering directory `/home/craigdo/repos/ns-3-allinone-test/ns-3-dev/build'
Waf: Leaving directory `/home/craigdo/repos/ns-3-allinone-test/ns-3-dev/build'
'build' finished successfully (0.939s)
FAIL: TestSuite propagation-loss-model
PASS: TestSuite object-name-service
PASS: TestSuite pcap-file-object
PASS: TestSuite ns3-tcp-cwnd
...
PASS: TestSuite ns3-tcp-interoperability
PASS: Example csma-broadcast
PASS: Example csma-multicast
This mode is intended to be used by users who are interested in determining if
their distribution is working correctly, and by developers who are interested
in determining if changes they have made have caused any regressions.
There are a number of options available to control the behavior of test.py.
if you run test.py --help you should see a command summary like:
Usage: test.py [options]
Options:
-h, --help show this help message and exit
-b BUILDPATH, --buildpath=BUILDPATH
specify the path where ns-3 was built (defaults to the
build directory for the current variant)
-c KIND, --constrain=KIND
constrain the test-runner by kind of test
-e EXAMPLE, --example=EXAMPLE
specify a single example to run (no relative path is
needed)
-d, --duration print the duration of each test suite and example
-e EXAMPLE, --example=EXAMPLE
specify a single example to run (no relative path is
needed)
-u, --update-data If examples use reference data files, get them to re-
generate them
-f FULLNESS, --fullness=FULLNESS
choose the duration of tests to run: QUICK, EXTENSIVE,
or TAKES_FOREVER, where EXTENSIVE includes QUICK and
TAKES_FOREVER includes QUICK and EXTENSIVE (only QUICK
tests are run by default)
-g, --grind run the test suites and examples using valgrind
-k, --kinds print the kinds of tests available
-l, --list print the list of known tests
-m, --multiple report multiple failures from test suites and test
cases
-n, --nowaf do not run waf before starting testing
-p PYEXAMPLE, --pyexample=PYEXAMPLE
specify a single python example to run (with relative
path)
-r, --retain retain all temporary files (which are normally
deleted)
-s TEST-SUITE, --suite=TEST-SUITE
specify a single test suite to run
-t TEXT-FILE, --text=TEXT-FILE
write detailed test results into TEXT-FILE.txt
-v, --verbose print progress and informational messages
-w HTML-FILE, --web=HTML-FILE, --html=HTML-FILE
write detailed test results into HTML-FILE.html
-x XML-FILE, --xml=XML-FILE
write detailed test results into XML-FILE.xml
If one specifies an optional output style, one can generate detailed descriptions
of the tests and status. Available styles are text and HTML.
The buildbots will select the HTML option to generate HTML test reports for the
nightly builds using
$ ./test.py --html=nightly.html
In this case, an HTML file named ‘’nightly.html’’ would be created with a pretty
summary of the testing done. A ‘’human readable’’ format is available for users
interested in the details.
$ ./test.py --text=results.txt
In the example above, the test suite checking the ns-3 wireless
device propagation loss models failed. By default no further information is
provided.
To further explore the failure, test.py allows a single test suite
to be specified. Running the command
$ ./test.py --suite=propagation-loss-model
or equivalently
$ ./test.py -s propagation-loss-model
results in that single test suite being run.
FAIL: TestSuite propagation-loss-model
To find detailed information regarding the failure, one must specify the kind
of output desired. For example, most people will probably be interested in
a text file:
$ ./test.py --suite=propagation-loss-model --text=results.txt
This will result in that single test suite being run with the test status written to
the file ‘’results.txt’‘.
You should find something similar to the following in that file
FAIL: Test Suite ''propagation-loss-model'' (real 0.02 user 0.01 system 0.00)
PASS: Test Case "Check ... Friis ... model ..." (real 0.01 user 0.00 system 0.00)
FAIL: Test Case "Check ... Log Distance ... model" (real 0.01 user 0.01 system 0.00)
Details:
Message: Got unexpected SNR value
Condition: [long description of what actually failed]
Actual: 176.395
Limit: 176.407 +- 0.0005
File: ../src/test/ns3wifi/propagation-loss-models-test-suite.cc
Line: 360
Notice that the Test Suite is composed of two Test Cases. The first test case
checked the Friis propagation loss model and passed. The second test case
failed checking the Log Distance propagation model. In this case, an SNR of
176.395 was found, and the test expected a value of 176.407 correct to three
decimal places. The file which implemented the failing test is listed as well
as the line of code which triggered the failure.
If you desire, you could just as easily have written an HTML file using the
--html option as described above.
Typically a user will run all tests at least once after downloading
ns-3 to ensure that his or her environment has been built correctly
and is generating correct results according to the test suites. Developers
will typically run the test suites before and after making a change to ensure
that they have not introduced a regression with their changes. In this case,
developers may not want to run all tests, but only a subset. For example,
the developer might only want to run the unit tests periodically while making
changes to a repository. In this case, test.py can be told to constrain
the types of tests being run to a particular class of tests. The following
command will result in only the unit tests being run:
$ ./test.py --constrain=unit
Similarly, the following command will result in only the example smoke tests
being run:
$ ./test.py --constrain=unit
To see a quick list of the legal kinds of constraints, you can ask for them
to be listed. The following command
will result in the following list being displayed:
Waf: Entering directory `/home/craigdo/repos/ns-3-allinone-test/ns-3-dev/build'
Waf: Leaving directory `/home/craigdo/repos/ns-3-allinone-test/ns-3-dev/build'
'build' finished successfully (0.939s)Waf: Entering directory `/home/craigdo/repos/ns-3-allinone-test/ns-3-dev/build'
bvt: Build Verification Tests (to see if build completed successfully)
core: Run all TestSuite-based tests (exclude examples)
example: Examples (to see if example programs run successfully)
performance: Performance Tests (check to see if the system is as fast as expected)
system: System Tests (spans modules to check integration of modules)
unit: Unit Tests (within modules to check basic functionality)
Any of these kinds of test can be provided as a constraint using the --constraint
option.
To see a quick list of all of the test suites available, you can ask for them
to be listed. The following command,
will result in a list of the test suite being displayed, similar to
Waf: Entering directory `/home/craigdo/repos/ns-3-allinone-test/ns-3-dev/build'
Waf: Leaving directory `/home/craigdo/repos/ns-3-allinone-test/ns-3-dev/build'
'build' finished successfully (0.939s)
Test Type Test Name
--------- ---------
performance many-uniform-random-variables-one-get-value-call
performance one-uniform-random-variable-many-get-value-calls
performance type-id-perf
system buildings-pathloss-test
system buildings-shadowing-test
system devices-mesh-dot11s-regression
system devices-mesh-flame-regression
system epc-gtpu
...
unit wimax-phy-layer
unit wimax-service-flow
unit wimax-ss-mac-layer
unit wimax-tlv
example adhoc-aloha-ideal-phy
example adhoc-aloha-ideal-phy-matrix-propagation-loss-model
example adhoc-aloha-ideal-phy-with-microwave-oven
example aodv
...
Any of these listed suites can be selected to be run by itself using the
--suite option as shown above. Examples are handled differently.
Similarly to test suites, one can run a single C++ example program
using the --example option. Note that the relative path for the
example does not need to be included and that the executables built
for C++ examples do not have extensions. Furthermore, the example
must be registered as an example to the test framework; it is not
sufficient to create an example and run it through test.py; it must
be added to the relevant examples-to-run.py file, explained below.
Entering
$ ./test.py --example=udp-echo
results in that single example being run.
PASS: Example examples/udp/udp-echo
You can specify the directory where ns-3 was built using the
--buildpath option as follows.
$ ./test.py --buildpath=/home/craigdo/repos/ns-3-allinone-test/ns-3-dev/build/debug --example=wifi-simple-adhoc
One can run a single Python example program using the --pyexample
option. Note that the relative path for the example must be included
and that Python examples do need their extensions. Entering
$ ./test.py --pyexample=examples/tutorial/first.py
results in that single example being run.
PASS: Example examples/tutorial/first.py
Because Python examples are not built, you do not need to specify the
directory where ns-3 was built to run them.
Normally when example programs are executed, they write a large amount of trace
file data. This is normally saved to the base directory of the distribution
(e.g., /home/user/ns-3-dev). When test.py runs an example, it really
is completely unconcerned with the trace files. It just wants to to determine
if the example can be built and run without error. Since this is the case, the
trace files are written into a /tmp/unchecked-traces directory. If you
run the above example, you should be able to find the associated
udp-echo.tr and udp-echo-n-1.pcap files there.
The list of available examples is defined by the contents of the ‘’examples’’
directory in the distribution. If you select an example for execution using
the --example option, test.py will not make any attempt to decide
if the example has been configured or not, it will just try to run it and
report the result of the attempt.
When test.py runs, by default it will first ensure that the system has
been completely built. This can be defeated by selecting the --nowaf
option.
$ ./test.py --list --nowaf
will result in a list of the currently built test suites being displayed, similar to:
propagation-loss-model
ns3-tcp-cwnd
ns3-tcp-interoperability
pcap-file
object-name-service
random-variable-stream-generators
Note the absence of the Waf build messages.
test.py also supports running the test suites and examples under valgrind.
Valgrind is a flexible program for debugging and profiling Linux executables. By
default, valgrind runs a tool called memcheck, which performs a range of memory-
checking functions, including detecting accesses to uninitialised memory, misuse
of allocated memory (double frees, access after free, etc.) and detecting memory
leaks. This can be selected by using the --grind option.
As it runs, test.py and the programs that it runs indirectly, generate large
numbers of temporary files. Usually, the content of these files is not interesting,
however in some cases it can be useful (for debugging purposes) to view these files.
test.py provides a --retain option which will cause these temporary
files to be kept after the run is completed. The files are saved in a directory
named testpy-output under a subdirectory named according to the current Coordinated
Universal Time (also known as Greenwich Mean Time).
Finally, test.py provides a --verbose option which will print
large amounts of information about its progress. It is not expected that this
will be terribly useful unless there is an error. In this case, you can get
access to the standard output and standard error reported by running test suites
and examples. Select verbose in the following way:
All of these options can be mixed and matched. For example, to run all of the
ns-3 core test suites under valgrind, in verbose mode, while generating an HTML
output file, one would do:
$ ./test.py --verbose --grind --constrain=core --html=results.html
TestTaxonomy
As mentioned above, tests are grouped into a number of broadly defined
classifications to allow users to selectively run tests to address the different
kinds of testing that need to be done.
- Build Verification Tests
- Unit Tests
- System Tests
- Examples
- Performance Tests
Moreover, each test is further classified according to the expected time needed to
run it. Tests are classified as:
- QUICK
- EXTENSIVE
- TAKES_FOREVER
Note that specifying EXTENSIVE fullness will also run tests in QUICK category.
Specifying TAKES_FOREVER will run tests in EXTENSIVE and QUICK categories.
By default, only QUICK tests are ran.
As a rule of thumb, tests that must be run to ensure ns-3 coherence should be
QUICK (i.e., take a few seconds). Tests that could be skipped, but are nice to do
can be EXTENSIVE; these are tests that typically need minutes. TAKES_FOREVER is
left for tests that take a really long time, in the order of several minutes.
The main classification goal is to be able to run the buildbots in a reasonable
time, and still be able to perform more extensive tests when needed.
BuildVerificationTests
These are relatively simple tests that are built along with the distribution
and are used to make sure that the build is pretty much working. Our
current unit tests live in the source files of the code they test and are
built into the ns-3 modules; and so fit the description of BVTs. BVTs live
in the same source code that is built into the ns-3 code. Our current tests
are examples of this kind of test.
Unit Tests
Unit tests are more involved tests that go into detail to make sure that a
piece of code works as advertised in isolation. There is really no reason
for this kind of test to be built into an ns-3 module. It turns out, for
example, that the unit tests for the object name service are about the same
size as the object name service code itself. Unit tests are tests that
check a single bit of functionality that are not built into the ns-3 code,
but live in the same directory as the code it tests. It is possible that
these tests check integration of multiple implementation files in a module
as well. The file src/core/test/names-test-suite.cc is an example of this kind
of test. The file src/network/test/pcap-file-test-suite.cc is another example
that uses a known good pcap file as a test vector file. This file is stored
locally in the src/network directory.
System Tests
System tests are those that involve more than one module in the system. We
have lots of this kind of test running in our current regression framework,
but they are typically overloaded examples. We provide a new place
for this kind of test in the directory src/test. The file
src/test/ns3tcp/ns3-interop-test-suite.cc is an example of this kind of
test. It uses NSC TCP to test the ns-3 TCP implementation. Often there
will be test vectors required for this kind of test, and they are stored in
the directory where the test lives. For example,
ns3tcp-interop-response-vectors.pcap is a file consisting of a number of TCP
headers that are used as the expected responses of the ns-3 TCP under test
to a stimulus generated by the NSC TCP which is used as a ‘’known good’’
implementation.
Examples
The examples are tested by the framework to make sure they built and will
run. Nothing is checked, and currently the pcap files are just written off
into /tmp to be discarded. If the examples run (don’t crash) they pass this
smoke test.
Running Tests
Tests are typically run using the high level test.py program. To get a list of the available command-line options, run test.py --help
The test program test.py will run both tests and those examples that
have been added to the list to check. The difference between tests
and examples is as follows. Tests generally check that specific simulation
output or events conforms to expected behavior. In contrast, the output
of examples is not checked, and the test program merely checks the exit
status of the example program to make sure that it runs without error.
Briefly, to run all tests, first one must configure tests during configuration
stage, and also (optionally) examples if examples are to be checked:
$ ./waf --configure --enable-examples --enable-tests
Then, build ns-3, and after it is built, just run test.py. test.py -h
will show a number of configuration options that modify the behavior
of test.py.
The program test.py invokes, for C++ tests and examples, a lower-level
C++ program called test-runner to actually run the tests. As discussed
below, this test-runner can be a helpful way to debug tests.
Debugging Tests
The debugging of the test programs is best performed running the low-level
test-runner program. The test-runner is the bridge from generic Python
code to ns-3 code. It is written in C++ and uses the automatic test
discovery process in the ns-3 code to find and allow execution of all
of the various tests.
The main reason why test.py is not suitable for debugging is that it is
not allowed for logging to be turned on using the NS_LOG environmental
variable when test.py runs. This limitation does not apply to the test-runner
executable. Hence, if you want to see logging output from your tests, you
have to run them using the test-runner directly.
In order to execute the test-runner, you run it like any other ns-3 executable
– using waf. To get a list of available options, you can type:
$ ./waf --run "test-runner --help"
You should see something like the following
Usage: /home/craigdo/repos/ns-3-allinone-test/ns-3-dev/build/utils/ns3-dev-test-runner-debug [OPTIONS]
Options:
--help : print these options
--print-test-name-list : print the list of names of tests available
--list : an alias for --print-test-name-list
--print-test-types : print the type of tests along with their names
--print-test-type-list : print the list of types of tests available
--print-temp-dir : print name of temporary directory before running
the tests
--test-type=TYPE : process only tests of type TYPE
--test-name=NAME : process only test whose name matches NAME
--suite=NAME : an alias (here for compatibility reasons only)
for --test-name=NAME
--assert-on-failure : when a test fails, crash immediately (useful
when running under a debugger
--stop-on-failure : when a test fails, stop immediately
--fullness=FULLNESS : choose the duration of tests to run: QUICK,
EXTENSIVE, or TAKES_FOREVER, where EXTENSIVE
includes QUICK and TAKES_FOREVER includes
QUICK and EXTENSIVE (only QUICK tests are
run by default)
--verbose : print details of test execution
--xml : format test run output as xml
--tempdir=DIR : set temp dir for tests to store output files
--datadir=DIR : set data dir for tests to read reference files
--out=FILE : send test result to FILE instead of standard output
--append=FILE : append test result to FILE instead of standard output
There are a number of things available to you which will be familiar to you if
you have looked at test.py. This should be expected since the test-
runner is just an interface between test.py and ns-3. You
may notice that example-related commands are missing here. That is because
the examples are really not ns-3 tests. test.py runs them
as if they were to present a unified testing environment, but they are really
completely different and not to be found here.
The first new option that appears here, but not in test.py is the --assert-on-failure
option. This option is useful when debugging a test case when running under a
debugger like gdb. When selected, this option tells the underlying
test case to cause a segmentation violation if an error is detected. This has
the nice side-effect of causing program execution to stop (break into the
debugger) when an error is detected. If you are using gdb, you could use this
option something like,
$ ./waf shell
$ cd build/utils
$ gdb ns3-dev-test-runner-debug
$ run --suite=global-value --assert-on-failure
If an error is then found in the global-value test suite, a segfault would be
generated and the (source level) debugger would stop at the NS_TEST_ASSERT_MSG
that detected the error.
To run one of the tests directly from the test-runner
using waf, you will need to specify the test suite to run.
So you could use the shell and do:
$ ./waf --run "test-runner --suite=pcap-file"
ns-3 logging is available when you run it this way, such as:
$ NS_LOG=”Packet” ./waf –run “test-runner –suite=pcap-file”
Test output
Many test suites need to write temporary files (such as pcap files)
in the process of running the tests. The tests then need a temporary directory
to write to. The Python test utility (test.py) will provide a temporary file
automatically, but if run stand-alone this temporary directory must be provided.
It can be annoying to continually have to provide
a --tempdir, so the test runner will figure one out for you if you don’t
provide one. It first looks for environment variables named TMP and
TEMP and uses those. If neither TMP nor TEMP are defined
it picks /tmp. The code then tacks on an identifier indicating what
created the directory (ns-3) then the time (hh.mm.ss) followed by a large random
number. The test runner creates a directory of that name to be used as the
temporary directory. Temporary files then go into a directory that will be
named something like
/tmp/ns-3.10.25.37.61537845
The time is provided as a hint so that you can relatively easily reconstruct
what directory was used if you need to go back and look at the files that were
placed in that directory.
Another class of output is test output like pcap traces that are generated
to compare to reference output. The test program will typically delete
these after the test suites all run. To disable the deletion of test
output, run test.py with the “retain” option:
and test output can be found in the testpy-output/ directory.
Reporting of test failures
When you run a test suite using the test-runner it will run the test
and report PASS or FAIL.
To run more quietly, you need to specify an output file to which the tests will write their status using the --out option.
Try,
$ ./waf --run "test-runner --suite=pcap-file --out=myfile.txt"
Debugging test suite failures
To debug test crashes, such as
CRASH: TestSuite ns3-wifi-interference
You can access the underlying test-runner program via gdb as follows, and
then pass the “–basedir=`pwd`” argument to run (you can also pass other
arguments as needed, but basedir is the minimum needed):
$ ./waf --command-template="gdb %s" --run "test-runner"
Waf: Entering directory `/home/tomh/hg/sep09/ns-3-allinone/ns-3-dev-678/build'
Waf: Leaving directory `/home/tomh/hg/sep09/ns-3-allinone/ns-3-dev-678/build'
'build' finished successfully (0.380s)
GNU gdb 6.8-debian
Copyright (C) 2008 Free Software Foundation, Inc.
L cense GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu"...
(gdb) r --suite=
Starting program: <..>/build/utils/ns3-dev-test-runner-debug --suite=ns3-wifi-interference
[Thread debugging using libthread_db enabled]
assert failed. file=../src/core/model/type-id.cc, line=138, cond="uid <= m_information.size () && uid != 0"
...
Here is another example of how to use valgrind to debug a memory problem
such as:
VALGR: TestSuite devices-mesh-dot11s-regression
$ ./waf --command-template="valgrind %s --suite=devices-mesh-dot11s-regression" --run test-runner
Class TestRunner
The executables that run dedicated test programs use a TestRunner class. This
class provides for automatic test registration and listing, as well as a way to
execute the individual tests. Individual test suites use C++ global
constructors
to add themselves to a collection of test suites managed by the test runner.
The test runner is used to list all of the available tests and to select a test
to be run. This is a quite simple class that provides three static methods to
provide or Adding and Getting test suites to a collection of tests. See the
doxygen for class ns3::TestRunner for details.
Test Suite
All ns-3 tests are classified into Test Suites and Test Cases. A
test suite is a collection of test cases that completely exercise a given kind
of functionality. As described above, test suites can be classified as,
- Build Verification Tests
- Unit Tests
- System Tests
- Examples
- Performance Tests
This classification is exported from the TestSuite class. This class is quite
simple, existing only as a place to export this type and to accumulate test
cases. From a user perspective, in order to create a new TestSuite in the
system one only has to define a new class that inherits from class TestSuite
and perform these two duties.
The following code will define a new class that can be run by test.py
as a ‘’unit’’ test with the display name, my-test-suite-name.
class MySuite : public TestSuite
{
public:
MyTestSuite ();
};
MyTestSuite::MyTestSuite ()
: TestSuite ("my-test-suite-name", UNIT)
{
AddTestCase (new MyTestCase, TestCase::QUICK);
}
static MyTestSuite myTestSuite;
The base class takes care of all of the registration and reporting required to
be a good citizen in the test framework.
Avoid putting initialization logic into the test suite or test case
constructors. This is
because an instance of the test suite is created at run time
(due to the static variable above) regardless of whether the test is being
run or not. Instead, the TestCase provides a virtual DoSetup method
that can be specialized to perform setup before DoRun is called.
Test Case
Individual tests are created using a TestCase class. Common models for the use
of a test case include “one test case per feature”, and “one test case per method.”
Mixtures of these models may be used.
In order to create a new test case in the system, all one has to do is to inherit
from the TestCase base class, override the constructor to give the test
case a name and override the DoRun method to run the test. Optionally,
override also the DoSetup method.
class MyTestCase : public TestCase
{
MyTestCase ();
virtual void DoSetup (void);
virtual void DoRun (void);
};
MyTestCase::MyTestCase ()
: TestCase ("Check some bit of functionality")
{
}
void
MyTestCase::DoRun (void)
{
NS_TEST_ASSERT_MSG_EQ (true, true, "Some failure message");
}
Utilities
There are a number of utilities of various kinds that are also part of the
testing framework. Examples include a generalized pcap file useful for
storing test vectors; a generic container useful for transient storage of
test vectors during test execution; and tools for generating presentations
based on validation and verification testing results.
These utilities are not documented here, but for example, please see
how the TCP tests found in src/test/ns3tcp/ use pcap files and reference
output.
How to write tests
A primary goal of the ns-3 project is to help users to improve the
validity and credibility of their results. There are many elements
to obtaining valid models and simulations, and testing is a major
component. If you contribute models or examples to ns-3, you may
be asked to contribute test code. Models that you contribute will be
used for many years by other people, who probably have no idea upon
first glance whether the model is correct. The test code that you
write for your model will help to avoid future regressions in
the output and will aid future users in understanding the verification
and bounds of applicability of your models.
There are many ways to verify the correctness of a model’s implementation.
In this section,
we hope to cover some common cases that can be used as a guide to
writing new tests.
Sample TestSuite skeleton
When starting from scratch (i.e. not adding a TestCase to an existing
TestSuite), these things need to be decided up front:
- What the test suite will be called
- What type of test it will be (Build Verification Test, Unit Test,
System Test, or Performance Test)
- Where the test code will live (either in an existing ns-3 module or
separately in src/test/ directory). You will have to edit the wscript
file in that directory to compile your new code, if it is a new file.
A program called src/create-module.py is a good starting point.
This program can be invoked such as create-module.py router for
a hypothetical new module called router. Once you do this, you
will see a router directory, and a test/router-test-suite.cc
test suite. This file can be a starting point for your initial test.
This is a working test suite, although the actual tests performed are
trivial. Copy it over to your module’s test directory, and do a global
substitution of “Router” in that file for something pertaining to
the model that you want to test. You can also edit things such as a
more descriptive test case name.
You also need to add a block into your wscript to get this test to
compile:
module_test.source = [
'test/router-test-suite.cc',
]
Before you actually start making this do useful things, it may help
to try to run the skeleton. Make sure that ns-3 has been configured with
the “–enable-tests” option. Let’s assume that your new test suite
is called “router” such as here:
RouterTestSuite::RouterTestSuite ()
: TestSuite ("router", UNIT)
Try this command:
Output such as below should be produced:
PASS: TestSuite router
1 of 1 tests passed (1 passed, 0 skipped, 0 failed, 0 crashed, 0 valgrind errors)
See src/lte/test/test-lte-antenna.cc for a worked example.
Test macros
There are a number of macros available for checking test program
output with expected output. These macros are defined in
src/core/model/test.h.
The main set of macros that are used include the following:
NS_TEST_ASSERT_MSG_EQ(actual, limit, msg)
NS_TEST_ASSERT_MSG_NE(actual, limit, msg)
NS_TEST_ASSERT_MSG_LT(actual, limit, msg)
NS_TEST_ASSERT_MSG_GT(actual, limit, msg)
NS_TEST_ASSERT_MSG_EQ_TOL(actual, limit, tol, msg)
The first argument actual is the value under test, the second value
limit is the expected value (or the value to test against), and the
last argument msg is the error message to print out if the test fails.
The first four macros above test for equality, inequality, less than, or
greater than, respectively. The fifth macro above tests for equality,
but within a certain tolerance. This variant is useful when testing
floating point numbers for equality against a limit, where you want to
avoid a test failure due to rounding errors.
Finally, there are variants of the above where the keyword ASSERT
is replaced by EXPECT. These variants are designed specially for
use in methods (especially callbacks) returning void. Reserve their
use for callbacks that you use in your test programs; otherwise,
use the ASSERT variants.
How to add an example program to the test suite
One can “smoke test” that examples compile and run successfully
to completion (without memory leaks) using the examples-to-run.py
script located in your module’s test directory. Briefly, by including
an instance of this file in your test directory, you can cause the
test runner to execute the examples listed. It is usually best to make
sure that you select examples that have reasonably short run times so as
to not bog down the tests. See the example in src/lte/test/
directory.
Testing for boolean outcomes
Testing outcomes when randomness is involved
Testing output data against a known distribution
Providing non-trivial input vectors of data
Storing and referencing non-trivial output data
Presenting your output test data
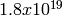 independent streams of random numbers,
each of which consists of
independent streams of random numbers,
each of which consists of 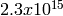 substreams. Each substream has a
period (i.e., the number of random numbers before overlap) of
substreams. Each substream has a
period (i.e., the number of random numbers before overlap) of
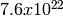 . The period of the entire generator is
. The period of the entire generator is 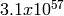 .
.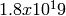 random variables. Each
random variable in a single replication can produce up to
random variables. Each
random variable in a single replication can produce up to 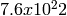 random numbers before overlapping.
random numbers before overlapping.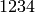 passed as a parameter. It turns out
that this operator is defined (by
passed as a parameter. It turns out
that this operator is defined (by