RandomNumberGenerators
Random Number Generator Validation Tests
Random numbers are sequences of numbers that contain no recongnizable patterns or regularities, biases or correlations. True randomness arises out of physical processes, such as Brownian motion, roulette wheels or dice, or can result from sensitive dependence on initial conditions (chaols). Random numbers generated by computers can simulate this property but do ultimately have repeating patterns. Algorithms that implement this behavior are called pseudo-random number generators.
Ns-3 can simulate many interesting deterministic processes, but if real phenomena that are governed by unpredictable events are to be included, the underlying source of unpredictability must be simulated by pseudo-random numbers. The different applications of randomness have led to many different methods for generating random numbers and also the requirement for various distributions of generated random numbers.
Since the goal of a stocahstic simulation is ultimately to mimic the behavior of some system that is really governed by a random process, the fidelity of the simulation is directly related to the fidelity of the random number generator driving the simulated process. Mathematician Robert Coveyou titled a paper written in 1969, "the generation of random numbers is too important to be left to chance."
There are many test suites for testing random number generator implementations. These range from the trivial to the incredibly sophisticated. Some of the most sophisticated tests are related to random number generators used in cryptographic appliations. For example, the U.S. National Institute of Standards and Technology (NIST) has developed, implemented and evaluated a suite of sixteen statistical tests for random number generators (see http://csrc.nist.gov/groups/ST/toolkit/rng/stats_tests.html). NIST provides a standards-based procedure for formal validation of a random number generator called the Random Number Generator Validation System (RNGVS). This level of testing is well behond the scope of ns-3 validation testing.
The random number generator used in ns-3 is the Combined Multiple Recursive Generator (MRG) MRG32k3a from Pierre L'Ecuyer (see http://www.iro.umontreal.ca/~lecuyer/myftp/papers/streams00.pdf). This generator is very well tested and has found a home in products such as MATLAB.
Our tests are relatively high-level tests designed to validate that the ns-3 implementation of the RNG and the various generated distributions behaves according to generally accepted statistical definitions.
Basic Concepts Used in the Tests
Every measurement of a random variable can be considered an individual. Repeated measurements genearate an aggregate of results called the population. If an infinite number of measurements is made, the result is called the parent population. The parent population is defined by a number of parameters. The basic goal of statistical analysis is to make an estimate of the parameters of the parent population along with some indication of the uncertainty of that estimate. The estimates are called statistics and are calculated from measured data.
Implicit in this is the fact that populations show variation. The study of variation requires the concept of frequency distribution. Given a random variable, called the variate, a frequency distribution specifies how often that variate takes on each of its possible values. A histogram is a commonly used tool for visualizing frequency distributions.
If a frequency distribution is described by an infinitesimal proportion of the population that resides in an infinitesimal interval, that differential description is called the probability density function (PDF). If this differential function is integrated, a cumulative density function (CDF) results. This function describes the proportion of the population for which the variate is less than the upper limit of integration.
An almost intuitive parameter used to describe a population is the mean or arithmetic average,
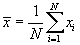 .
.
The deviation is the absolute value of the difference beteeen a particular measurement and some value, generally the average. The variance is defined as the average value of the square of the individual deviations,
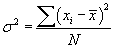 .
.
The standard deviation is the square root of the variance,
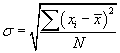 .
.

Hypothesis Testing
The goal of hypothesis testing is to make a determination that some aggregate of measured data match a model well enough to accept the data as, in fact, matching the model.
Technically, we propose a "Null Hypothesis" that the data do match the model. If we determine this is the case, we will have determined that the data and the model are drawn from the same population distribution. We also propose an "Alternate Hypothesis" that the data do not match.
We first histogram the measurement data to establish an esitmate for the probability density function (PDF). We use a known PDF to create a matching histogram that represents the parent population PDF. The expected frequency for a given bin in the model histogram is calculated from the difference between the cumulative distribution function evaluated at the upper limit of the bin and the lower limit of the bin. This must be multiplied by the sample size.
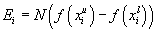 .
.
Pearson's test, also known as the chi-squared test is often used to come up with a quantitative description of the differences between the measured PDF and the parent population PDF.
In this statistic, the measured data is aggregated into a histogram indicated by the n variable below. The model histogram is aggregated into a histogram indicated by the m variable. The square root of the m variable is the standard deviation of the indexed model bin based on Poisson statistics.
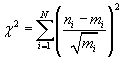 .
.

The chi-squared statistic is basically the sum of the squared deviations scaled by the expected statistical variation of the bin. It is easy to see that if the measured data matches the model "well," the resulting chi-squared statistic will be a relatively small number. If the measured data does not match the model, the resulting chi-squared statistic will be a relatively large number.
The trick is to define when a large number is "too large" and indicates that the model and data are not matched by some criterion. It turns out that the chi-squared statistic itself follows a probability distribution function. More precisely it follows a family of PDFs defined by a degrees of freedom parameter. The degrees of freedom (k) are the number of bins in the histogram minus the number of estimated parameters (an esitmated parameter would be the mean calculated from the data itself).
Just like a population has a cumulative density function, the chi-square distribution has a density function. We can use this CDF to determine confidence limits on a chi-squared statistic. In a one-sided test, the point at which 95% of the population of the chi-square distribution is to the left of the point indicates the 95 percent confidence limit. This means that if a chi-squared statistic is found to be lower than this value, it can be stated that variations between the measured data and the model are due to random chance with a 95% certainty. Conversely, if a chi-squared statistic is found to be greater than this 95% confidence limit, there is only a five percent chance that the data could be so bad due to chance alone.
The Basic Algorithm
As described above, the algorithm for the random number generator validation tests is essentially identical.
- Determine the range of the random number function of interest. For example, for the uniform generator the range is [0,1). The histogram bins must be arranged to cover the range in a reasonable way, and ensure that no bin will hold less than five counts when the model histogram is constructed. This often means extending the first, last or both bins in the histogram to infinity, while leaving the center bins uniformly spaced.
- The second step is to generate expected count values for the model histogram based on the CDF of the RNG under test.
- Make some large number of measurements (we use 1 000 000) and use these measurements to populate the measured data histogram that will be the object of the comparison.
- Calculate the chi-squared statistic itself. This will be represent the difference between the model and the data.
- Compare the chi-squared statistic with the 95% confidence limit value of that statistic. We use the number of histogram bins as the number of degrees of freedom since we do not estimate any of the parameters. The parameters are given as part of the description of the test itself.
Results
- Uniform Random Number Generator
- Normal Random Number Generator
- Exponential Random Number Generator
- Pareto Random Number Generator
The following is an illustration of how a failure would appear.
Craigdo 07:53, 30 May 2009 (UTC)